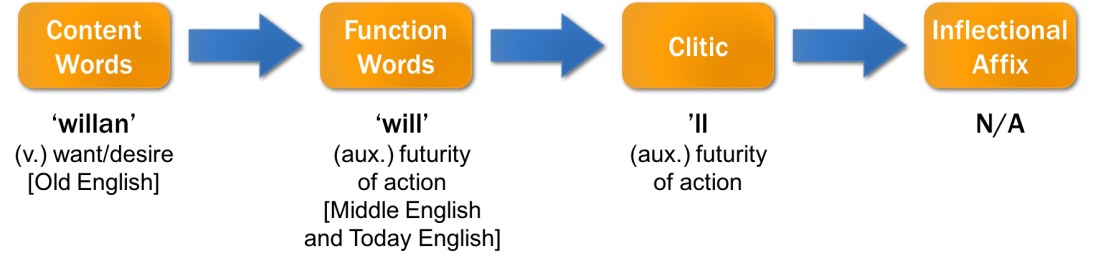
Let’s recollect the beginning of our quest to linguistics. We’re endeavoring to demystify the development of human language inside our brain. In Chomsky’s (1959, 1980) Poverty of the Stimulus argument, children rapidly form a mental grammar out of a small amount of linguistic stimuli within the first two years of their lives. Moreover, universal properties of natural language are extensively studied and later summarized as a large compendium (Dryer and Haspelsmith, 2005, 2013). These discoveries bolster the notion of Universal Grammar.
The Universal Grammar Theory postulates the existence of an innate and genetic component necessary for human’s ability to learn and generate language. The term Universal Grammar is sometimes to referred to as the mental grammar, and they can be used interchangeably. The theory is based on the Principles and Parameters Framework (P&P), whereby natural language is described by:
- Principles (abstract rules): a certain set of general structural rules are innate to humans and independent from sensory experience. For example, basic word order (the linear arrangement of subject, verb, and object) is a principle.
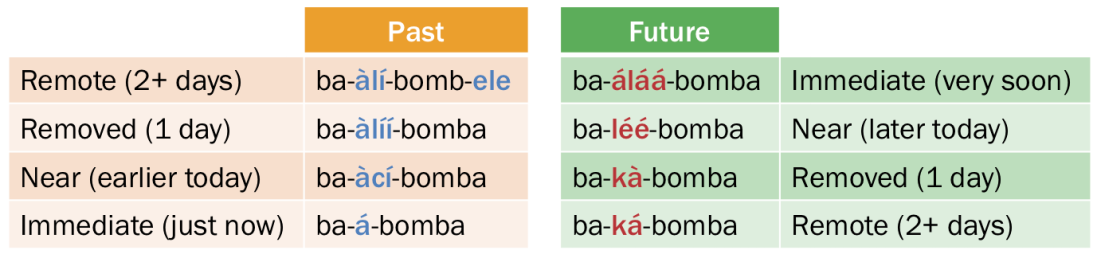
- Parameters (switches): with more linguistic stimuli received during psychological development, children adopt specific structural rules that conform to the principles. Most of these switches are binary (i.e. either on or off) and the remainders have discrete values. These values vary from language to language. For example, the basic word order of Mandarin Chinese is SVO while that of Japanese is SOV.
The framework is sometimes called Government and Binding. The Principles component is compared to a set of general rules that govern human language, and the Parameters component to binding the general rules to a particular language.
We can describe the language development in children with the P&P Framework as depicted in the following illustration.
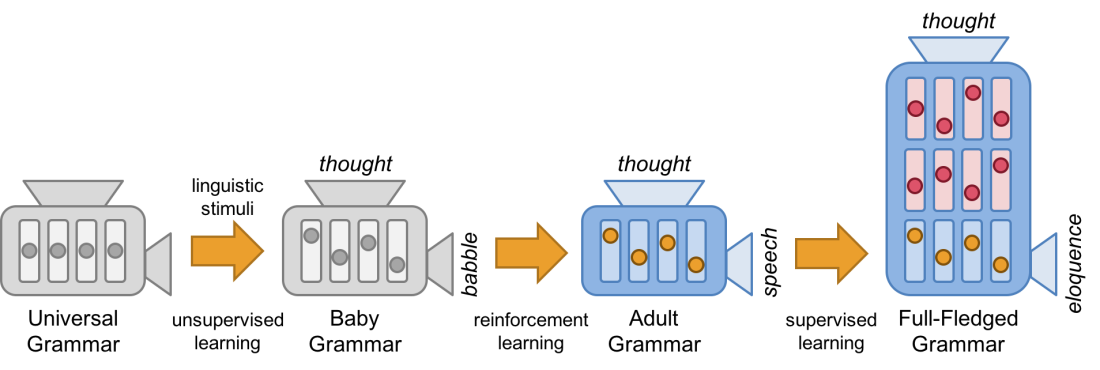
Step 1: A child is born with language faculty, which is actually an innate set of general structural rules. Let’s compare this set of rules with an uninitialized sausage machine (i.e. language principles).
Step 2: As the child is getting exposed to the linguistic stimuli from his parents, he learns to discern human voices from background noise and imitates the language by babbling. We consider this step unsupervised learning, because he learns this task from the stimuli without any explicitly labeled examples for human voice classification. At the end of this step, the sausage machine becomes partially initialized as some switches (i.e. language parameters) are turned on or off while the rest are left untouched. The child is ready to recognize and produce human voice, but he’s still unable to produce any grammatical sentences yet.
Step 3: His parents correct the child’s language use throughout the one-word, two-word, and telegraphic stages. He gradually acquires the language, or ‘tunes up the switches’, from positive and negative feedback from the parents. We consider this step a kind of reinforcement learning, owing to his objective to learn an appropriate language use from the guiding feedback. At the end of this step, the sausage machine becomes fully initialized. The child has achieved an adult grammar and is ready to produce an infinite number of grammatical sentences with respect to the grammar.
Step 4: The child gets exposed to human community. He keeps acquiring more fine-grained grammatical rules from the community’s language culture and attaching additional switches and wires to the sausage machine accordingly. We consider this step supervised learning, because the child learns the language use from explicitly labeled examples. Thanks to the very sophisticated sausage machine, the child is now capable of producing not only speech but also eloquence with his full-fledged grammar.
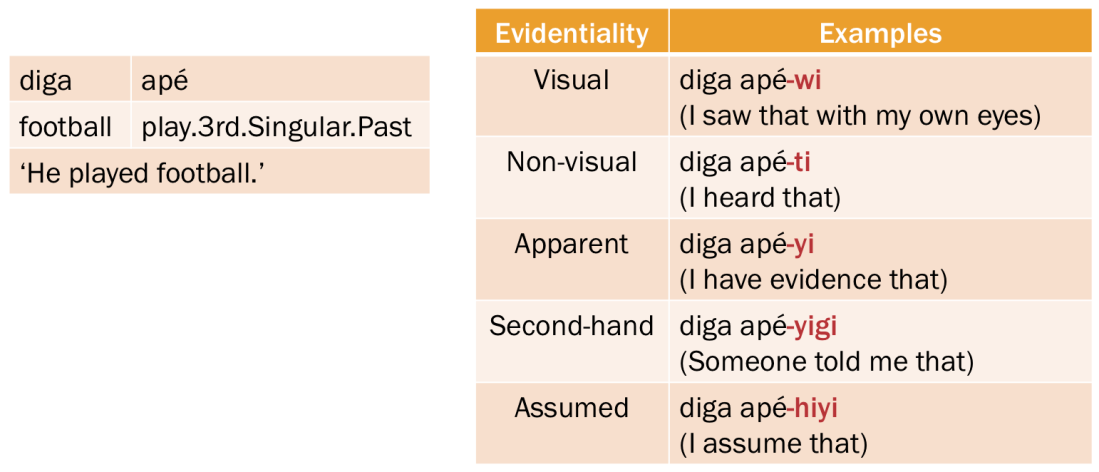
The Universal Grammar Theory is still an ongoing debate. The most common criticisms of the theory are three folds (Hinzen, 2012). First, despite its claim, any panlinguistically consistent formulation of the Universal Grammar has not been established. The notion of grammar rules employed in linguistics is post-hoc observations about existing languages rather than speculation about what is possible for a language (Sampson, 2005). Second, Christian and Chater (2008) argue that the innateness of the Universal Grammar contradicts the neo-Darwinian evolution theory. That is because evolution is a long process of genetic mutation whilst human’s use of language started in a much faster rate. Third and last, linguistic principles that generalize across all languages have not been discovered up until now. Even the notions of subject and object are not entirely universal. For example, Cebuano discerns the topic subject from the non-topic one with the absolutive and ergative case markers, respectively, while the object is marked by the oblique case marker (Dryer, 2013). Therefore, some connectionists believe that language learning is based on similarity by observing probabilistic patterns of words, a.k.a. distributional semantics (McDonald, 2001).
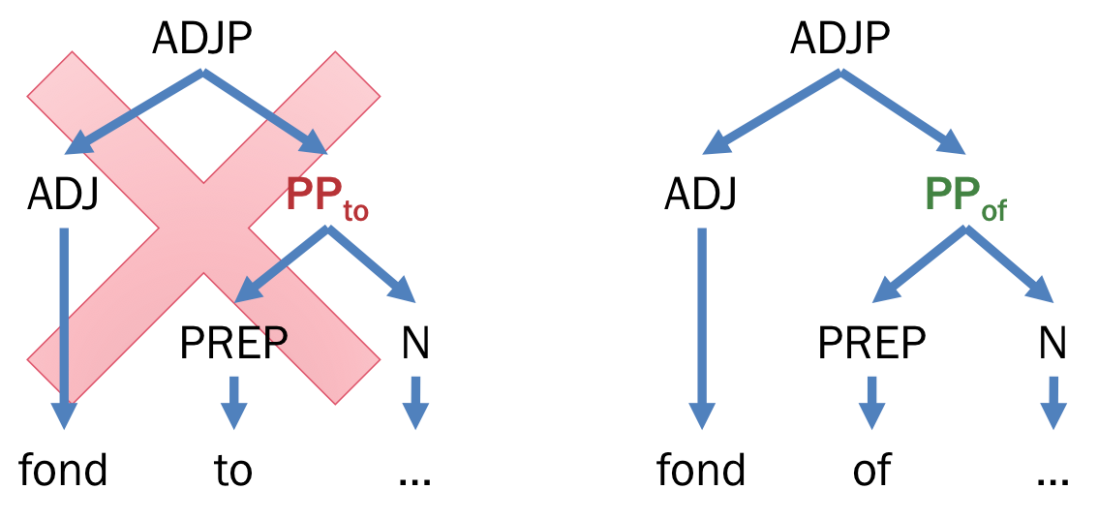
Despite the criticisms, the P&P Framework was shown to be a key catalyst for grammar induction (grammar discovery from raw text). In such task, we assume that words that co-occur frequently are likely to form a constituent such as a determiner and a noun, occurring very frequently, form a valid constituent. However, unexpected cooccurrence may lead to mistaken constituency. For example, a determiner and an adjective co-occur very frequently in English but they don’t form a grammatical constituent, e.g. grammatical [a [big dog]] vs. ungrammatical * [[a big] dog]. Various degrees of linguistic insights are employed to solve this issue (Haghighi and Klein, 2006; Druck et al., 2009; Snyder et al., 2009; Naseem et al., 2010; Boonkwan and Steedman, 2011; Bisk and Hockenmaier, 2012; Boonkwan, 2014), therefore substantially improving the accuracy of unsupervised parsing. Some of Boonkwan’s (2014) language parameters include:
- Basic word order
- Subject, verb, direct object, and indirect object (or free word order)
- Noun and its adjuncts and specifiers
- Verb and its complements, adjuncts, and specifiers
- Adposition (pre- and post-position) and its complements, adjuncts, and specifiers
- Copula (verb to be)
- Auxiliary verb and its complements, adjuncts, and specifiers
- Movement and extraction
- Dropping and ellipsis
- Coordinate structures
Elicitation of these language parameters can be done via a questionnaire-based interview with language informants. In the experiments, the informants are asked to translate a set of simple and complex sentences to their native languages. Language parameters are then extracted from the word alignment information and employed as the choice preferences of constituent formation.
References
- Chomsky, A. Noam (1959). “A Review of Skinner’s Verbal Behavior”. Language. LSA. 35 (1): 26–58. doi:10.2307/411334. Retrieved 2014-08-26., Repr. in Jakobovits, Leon A.; Miron, Murray S. (eds.). Readings in the Psychology of Language. New York: Prentice-Hall. pp. 142–143.
- Chomsky, N. (1980) On Cognitive Structures and their Development: A reply to Piaget. In M. Piattelli-Palmarini, ed. Language and Learning: The debate between Jean Piaget and Noam Chomsky. Harvard University Press.
- Dryer, Matthew S. & Haspelmath, Martin (eds.) 2005, 2013. The World Atlas of Language Structures Online. Leipzig: Max Planck Institute for Evolutionary Anthropology. (Available online at http://wals.info, Accessed on 2017-12-25.)
- Aria Haghighi and Dan Klein. 2006. Prototype-driven grammar induction. In Proceedings of 44th Annual Meeting of the Association for Computational Linguistics, pages 881–888.
- Gregory Druck, Gideon Mann, and Andrew McCallum. 2009. Semi-supervised learning of dependency parsers using generalized expectation cri- teria. In Proceedings of 47th Annual Meeting of the Association of Computational Linguistics and the 4th IJCNLP of the AFNLP, pages 360–368, Suntec, Singapore, August.
- Benjamin Snyder, Tahira Naseem, and Regina Barzilay. 2009. Unsupervised multilingual grammar induction. In Proceedings of the Joint Confer- ence of the 47th ACL and the 4th IJCNLP.
- Tahira Naseem, Harr Chen, Regina Barzilay, and Mark John- son. 2010. Using universal linguistic knowledge to guide grammar induction. In Proceedings of EMNLP-2010.
- Prachya Boonkwan and Mark Steedman. 2011. Grammar induction from text using small syntactic prototypes. In Proceedings of the 5th IJCNLP, pages 438–446.
- Yonatan Bisk and Julia Hockenmaier. 2012. Induction of linguistic structure with combinatory categorial grammars. In Proceedings of the NAACL-HLT Workshop on the Induction of Linguistic Structure, pages 90–95. ACL.
- Prachya Boonkwan. 2014. Scalable Semi-Supervised Grammar Induction using Cross-Linguistically Parameterized Syntactic Prototypes. PhD thesis. University of Edinburgh.
Copyright (C) 2018 by Prachya Boonkwan. All rights reserved.
The contents of this blog is protected by U.S., Thai, and International copyright laws. Reproduction and distribution of the contents of this blog without written permission of the author is prohibited.

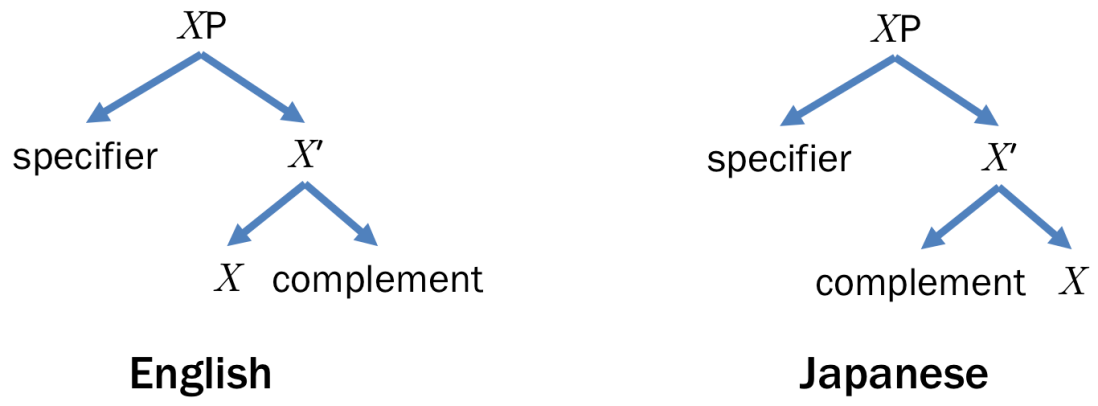
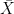 ) comes from an intermediate phrase type that represents the smallest complete core meaning formed by the head of type X and its complements. Here, X is actually a variable for any phrase type or part of speech such as N (noun), V (verb), and P (preposition).
) comes from an intermediate phrase type that represents the smallest complete core meaning formed by the head of type X and its complements. Here, X is actually a variable for any phrase type or part of speech such as N (noun), V (verb), and P (preposition).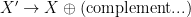
 is string concatenation in any order. Note that any constituent of type Xʹ conveys the smallest complete core meaning of the head of type X and it needs not be grammatical. For example, consider the constituent “gave a policeman a flower”. The ditransitive verb ‘gave’ requires two objects—a direct object and an indirect object. When this verb of type V combines with the two complements, i.e. ‘a policeman’ and ‘a flower’, the whole constituent becomes of bare phrase type Vʹ. We sometimes call a constituent of type Xʹ a bare phrase.
is string concatenation in any order. Note that any constituent of type Xʹ conveys the smallest complete core meaning of the head of type X and it needs not be grammatical. For example, consider the constituent “gave a policeman a flower”. The ditransitive verb ‘gave’ requires two objects—a direct object and an indirect object. When this verb of type V combines with the two complements, i.e. ‘a policeman’ and ‘a flower’, the whole constituent becomes of bare phrase type Vʹ. We sometimes call a constituent of type Xʹ a bare phrase.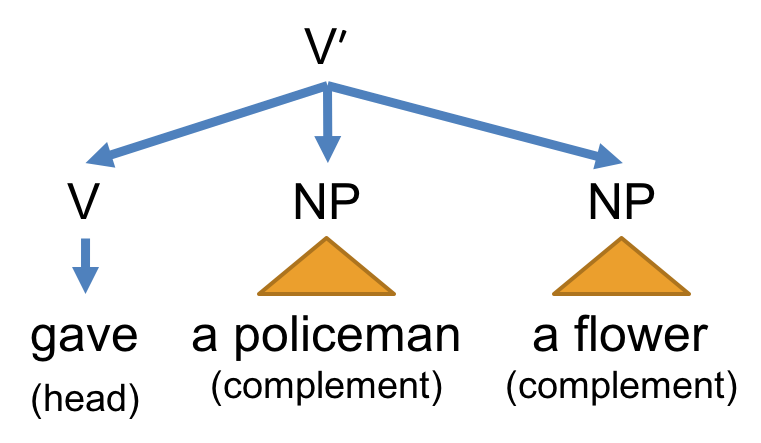
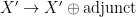
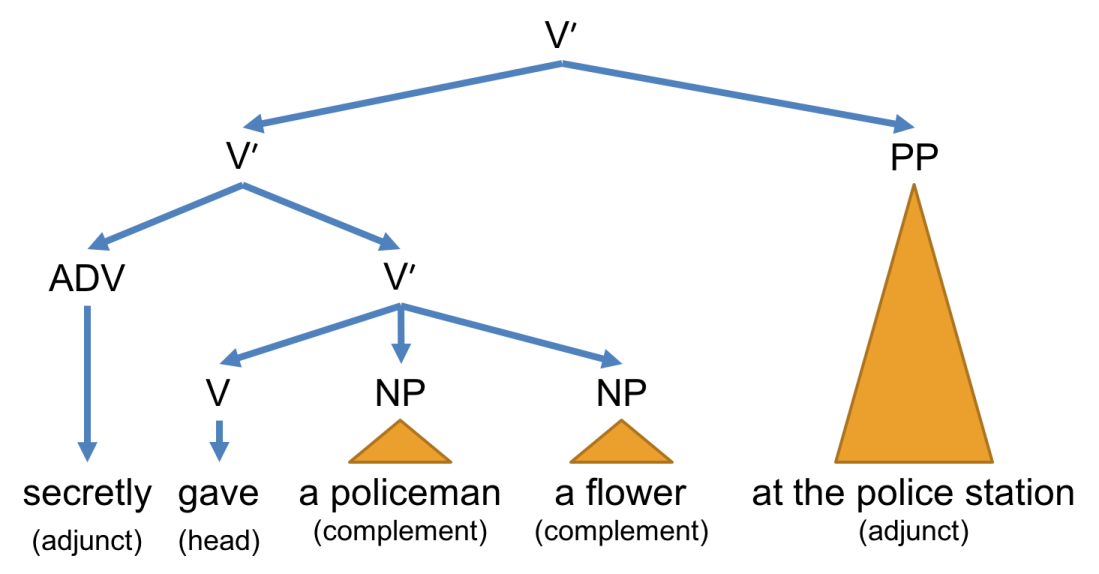
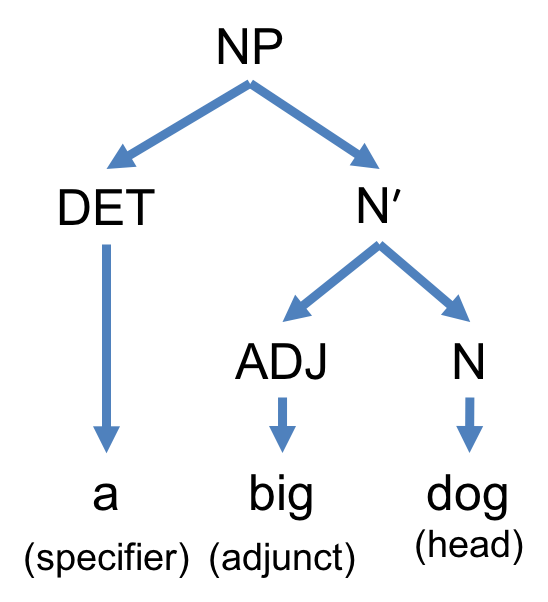

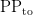 and
and  , the phrase structures will become as follows.
, the phrase structures will become as follows.